Optimization
검증세트 분리법
훈련을 많이 시키면 훈련 데이터에 대해서 좋은 성능이 나온다. 따라서 전체 데이터가 주어졌을때 20% 정도는 훈련시키지 않고 나중에 검증을 위하여 사용한다. 이러한 방식을 검증세트 분리라고 하며 8:2가 고루 섞이도록 잘 분류해야 한다.
분리의 예는 아래와 같다.
from sklearn.model_selection import train_test_split
x_train_all, x_test, y_train_all, y_test = train_test_split(x, y, stratify=y, test_size=0.2, random_state=42)
확률적 경사하강법
전체 샘플을 모두 선택하여 gradient를 계산하는 배치 경사하강과는 달리, 확률적 경사하강법에서는 샘플을 무작위로 뽑아서 계산하여 최적화 한다.
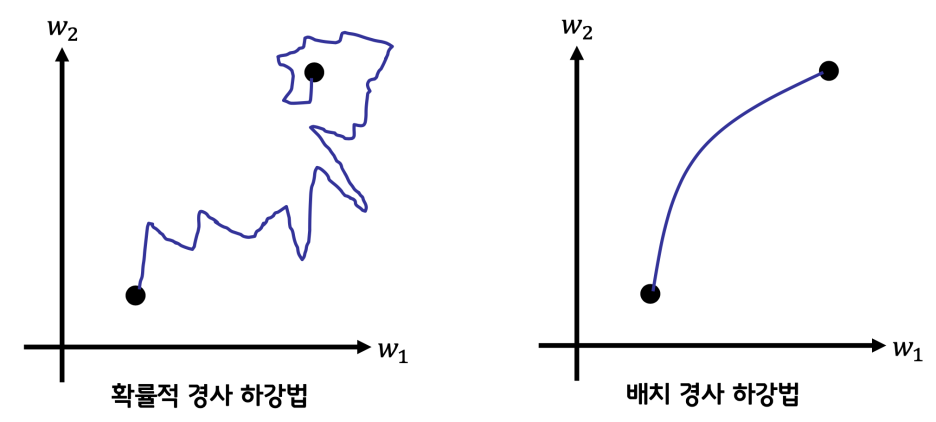
전체의 평균으로 구하는 배치경사처럼 완만하게 찾아가지는 않는다. 배치경사의 경우 행렬곱을 통해 한방에 계산한다. 진정한 MSE라고 할 수 있다.
indexes = np.random.permutation(np.arrage(len(x))) # index를 섞는 코드
스케일링
여러개의 weight가 있을 때, weight 값들에 대한 결과의 편차가 적은게 있고 큰게 있을 수 있다. 적은 경우 학습의 효율이 떨어지므로 정규화를 통해 스케일을 키워서 훈련시키면 성과가 더 좋다.
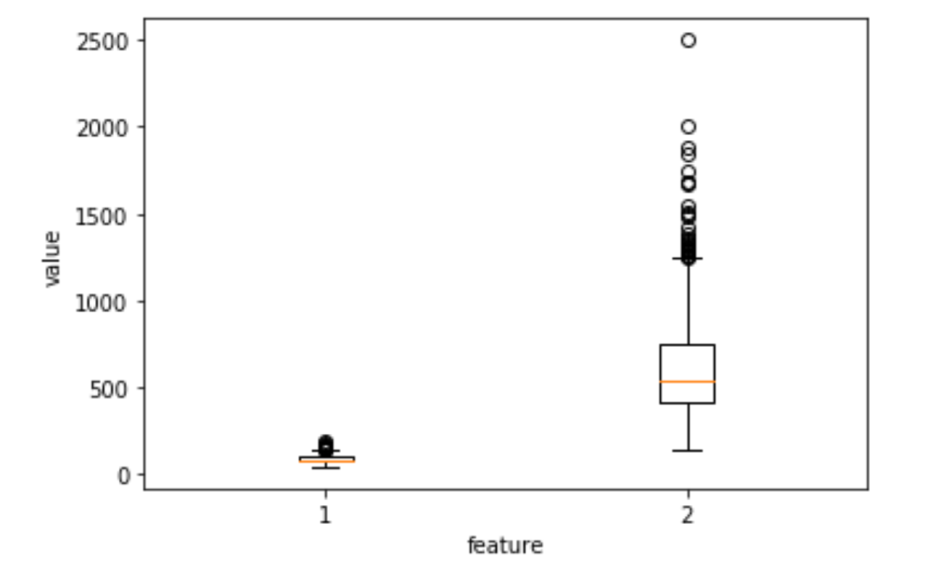
train_mean = np.mean(x_train, axis=0)
train_std = np.std(x_train, axis=0)
x_train_scaled = (x_train - train_mean) / train_std # 평균을 빼고 표준편차로 나눠서 정규화
과대적합, 과소적합
퀀트투자에서 백테스트를 할때, 너무 최적화하면 이론상으로 수익률이 엄청 크게 나올 수 있지만 현실에 반영이 안된다. 이것과 유사한 것 같다.
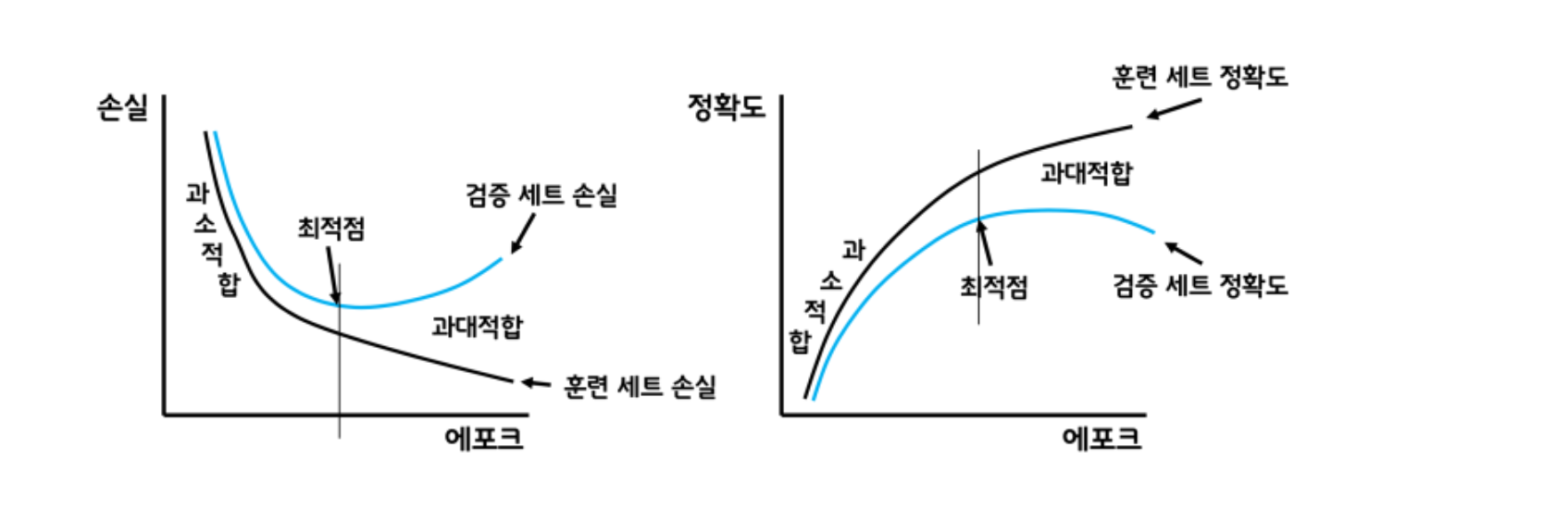
훈련세트의 손실(가설과 정답의 차)과 검증세트의 손실이 역전되는 정도의 epoch를 찾아서 그만큼 학습시키는 것이 좋다.
L1 규제
골자는 천천히 학습되도록 해서 소외되는 점이 없도록 한다이다. 손실에 노름이란 값을 더해서 손실을 늘려서 학습을 느리게 만든다.
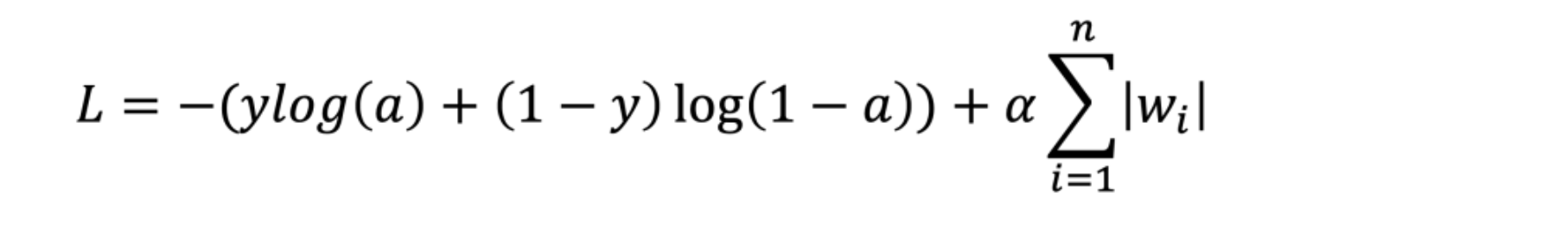
뒤에 알파값은 가중치이고 시그마가 노름이다. 손실(L)이 늘어난다. 회귀모델에 L1 규제를 추가한 것을 라쏘모델이라고 한다.
L2 규제
노름의 제곱을 더한다. 규제가 좀 더 쎄다. L2 규제를 추가한것을 릿지 모델이라고 한다.
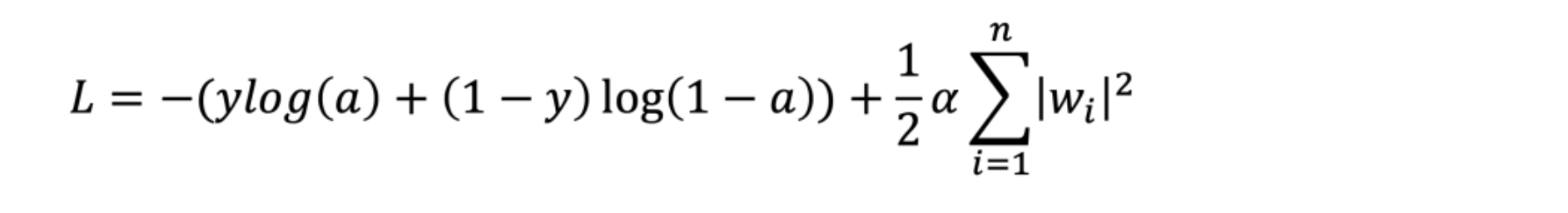
그런데 보통 L1, L2를 같이 쓴다. 앞에 가중치들을 조절할 뿐. 그리고 너무 쎄게 하면 학습이 안된다. 이를 적절하게 조절해야 한다. 또 하이퍼 파라메터다.
교차 검증구현
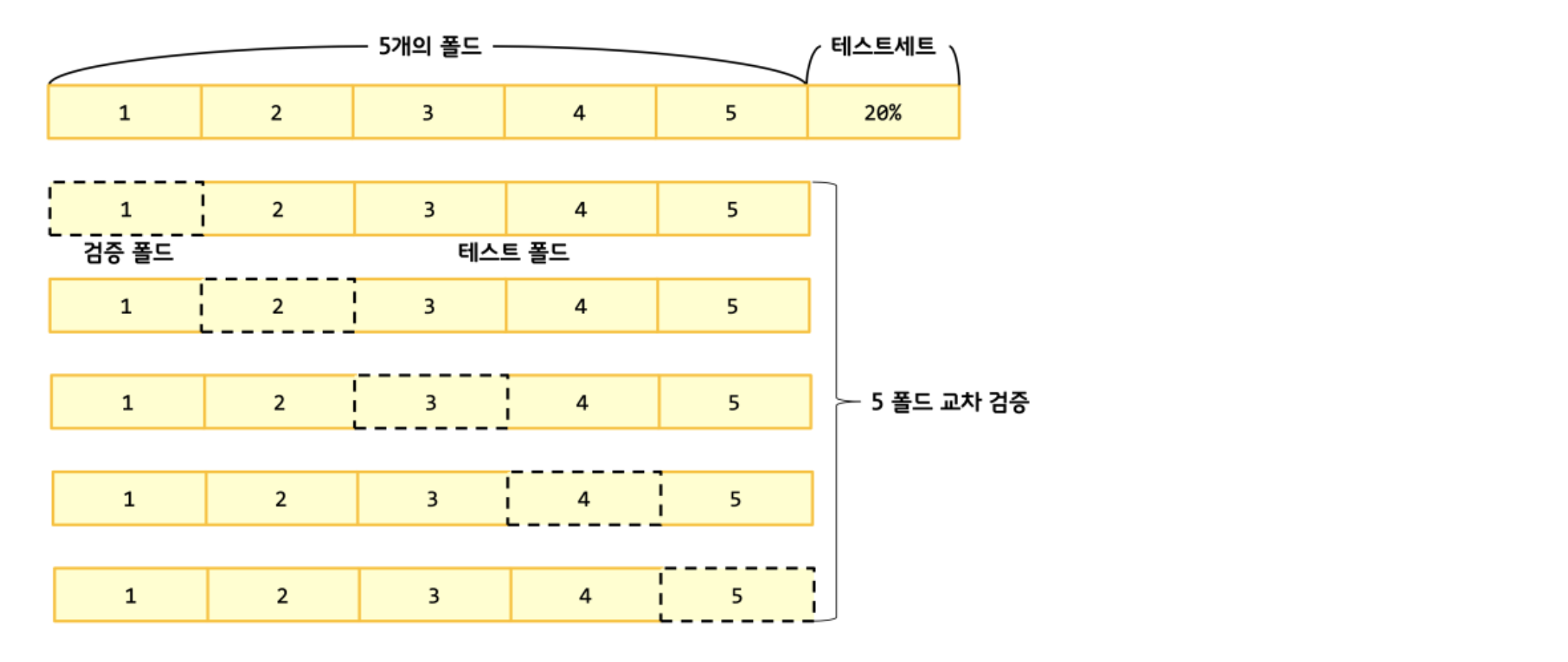
- 훈련 세트를 k개의 폴드(fold)로 나눈다.
- 첫 번째 폴드를 검증 세트로 사용하고 나머지 폴드(k-1개)를 훈련 세트로 사용 한다.
- 모델을 훈련한 다음에 검증 세트로 평가 한다.
- 차례대로 다음 폴드를 검증 세트로 사용하여 반복한다.
- k개의 검증세트로 k번 성능을 평가한 후 계산된 성능의 평균을 내어 최종성능을 계산한다.
배치 경사 하강법과 비슷하지만 에포크마다 전체 데이터를 사용하는 것이 아니라 조금씩 나누어 계산을 수행하고 그레디언트를 구하여 가중치를 업데이트 한다.
가중치 업데이트 방법
- 작게 나눈 미니 배치만큼 가중치를 업데이트 한다.
- 미니 배치의 크기는 보통 16,32,64등 2의 배수를 사용한다.
- 미니 배치의 크기가 1이면 확률적 경사 하강법이 된다.
- 미니배치의 크기가 작으면 확률적 경사하강법처럼 작동하고 크면 배치 경사하강법처럼 작동한다.
- 미니 배치의 크기도 하이퍼파라미터이고 튜닝의 대상이다.